Inside the NYPL Blog Redesign
For the past few months, NYPL Digital has worked on redesigning the blog platform on nypl.org in collaboration with DevSpark. The design highlights all the great blog posts from NYPL, as well as the series, channels, and authors on their own landing pages. Internally, the Blog app went through a few technical hurdles that helped solve problems we were facing on our other React projects. We’ll go through some issues we encountered as well as workflow improvements we got out of redesigning NYPL Blogs in React.

React Boilerplate
The Digital team created projects in React—Staff Picks, Book Lists, New Arrivals, Homepage, and Search Beta—and they all have a similar foundation built on Express and server side rendered React code. In order to speed the process of building on top of the foundation, we built a boilerplate that uses Express, React, React Router, and Alt.
We found that the boilerplate helped the developers from DevSpark start the Blog app quickly without the usual initial process of deciding the app architecture or technology. The boilerplate is optimized to use the technologies we have experienced and knowledge with. Overall, this was a great boon to our development workflow.
While developing this NYPL boilerplate, the Create React App came out. This project helps start a React application quickly with no build configuration. This project is great and we hope to further investigate and build on top of it with custom NYPL components.
Initial Strategy
A great aspect about React is that it’s Javascript with a bit more added syntax for HTML markup, and we therefore spent more time discussing how we were going to build the app rather than the framework around it. We began the process by first going over the general layout components needed for the page and then the smaller components that would fit into the layout components. We found, of course, that the React documentation helped tremendously. From the documentation, we built our own picture of how the pages in the app should be composed.

After creating reusable components, we put them to the test by passing different data sets to them as props. We started from the main landing page and then moved on to specific landing pages for blog series, subjects, and authors, and those pages also used these components. For the initial approach, we began with a few routes but made it easy to add more routes in the future. These first routes helped create the app foundation.
As we progressed we decided to add a route for blogger profiles located at /blog/authors and to also include "beta" in the route while we are in the beta stage of development.
Upgrading to React Router 2.0
Creating the routes was simple compared to implementing them. We started this project in React 0.13 and React Router 0.13. We had already upgraded our other React apps to React 0.14 but updating to React Router 2.0 was a more involved process. Not only were we two big versions behind, but there were many breaking changes in the newer versions. To make the upgrade process easier we first upgraded from version 0.13 to version 1.0 and then to version 2.0, and I’ll briefly discuss some changes we made.
One change we faced was updating the Route components. This was an interesting update because it also changed the concept of how we were routing in the app. Routing to a state or route was updated to routing to a path. This meant that now we were linking to specific URLs instead of defined states.
Another big update was how we rendered the routes on the server side. This took a lot of investigation because we also use Alt and Iso for data management and that had to be included in the app architecture. This update better facilitated how we redirect and render pages when we run into server errors.
We went from using React 0.13 and React Router 0.13 syntax.
The jump from version 0.13 to version 2.0 also helped push conventions we were using. For example, we were using the `Navigation` mixin to transition between routes. There were two issues with using the mixin: you had to use an ES5 class to compose the component and using mixins was not the functional and compositional pattern we wanted to us. The `Navigation` mixin was replaced by the `History` mixin but we found no need to use it, and so we were able to fully embrace the ES6 syntax convention by upgrading our ES5 components to ES6 components.
Conventions
Besides the ES6 class component syntax convention, we developed more department-wide conventions to use in our applications. We encouraged and supported the use of ES6 syntax by running our code through ESLint and using AirBnb's ESLint configuration. When making pull requests we made running the new feature or bug fix through ESLint.
The API endpoints we use for blog data are big due to the nature of the data. Lists of blog posts can be long and it takes time to aggregate all the data needed to display. Because of the transition times between routes in the app, we added a loading state with the name of the page that is being navigated to. For example, going from a blog post page to the blog landing page will display a loader like the following:

When navigating to a specific blog post, series, author, or subject, the name of the selected page will be displayed.

This loader is also the same loader that is used on the Search app which is still in beta.

This is now a convention that we plan to use in New Arrivals, Staff Picks, and Book Lists.
Using NYPL Header and Footer as npm modules
At the time of developing the Blog beta app, development also went into New Arrivals, the homepage on nypl.org, and the header. React components were shared across the apps and they were used as modules added through BitBucket repositories in the application’s `package.json` file.
This worked well but there were occasions where we ran into permission issues when installing and when deploying to different servers. To get a more streamline workflow, we open sourced the NYPL Header and Footer components and made them into npm modules. Blog Beta and Search Beta are now the first applications to use these modules in production.
You can find more information about the Header and the Footer on npm.
HTML5 Markup
One improvement we wanted to make for blogs is to make them more accessible to web crawlers and screen readers. The NYPL Header and Footer, discussed previously, render as <header> and <footer> tags but the rest of the page have basic HTML tags. There’s nothing wrong with using divs but to add better semantics to the page, we broke apart the layout using HTML5 elements.
Some of the main elements we used are <section>, <article>, <main>, <aside>, and <address>. There’s no visual change to this update, but the update makes it easier for screenreaders to navigate the page and get to the content easily. If a patron wanted to get in contact with the blog author of a blog post, for example, they can navigate to the <address> element and easily find an author’s information. There is no specific recipe for creating semantic blog posts but we are working with accessibility teams at NYPL to better improve the user experience.
The Blog redesign is a small part of the nypl.org update, but the Digital team was able to push conventions and code changes from it. The redesign is in beta as we are working to include features and optimize the app but please explore and send us your feedback.
Read E-Books with SimplyE
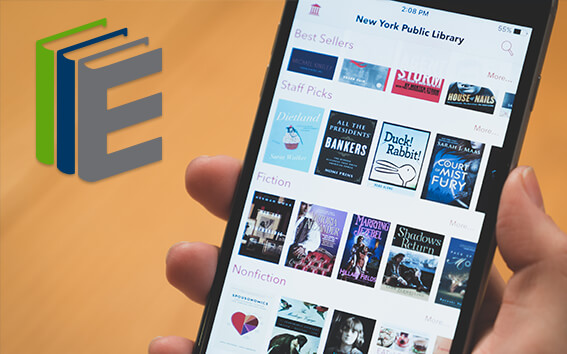 With your library card, it's easier than ever to choose from more than 300,000 e-books on SimplyE, The New York Public Library's free e-reader app. Gain access to digital resources for all ages, including e-books, audiobooks, databases, and more.
With your library card, it's easier than ever to choose from more than 300,000 e-books on SimplyE, The New York Public Library's free e-reader app. Gain access to digital resources for all ages, including e-books, audiobooks, databases, and more.
If you don’t have an NYPL library card, New York State residents can apply for a digital card online or through SimplyE (available on the App Store or Google Play).
Need more help? Read our guide to using SimplyE.