NYPL Labs
Nomadic Classification: Classmark History and New Browsing Tool
In the past few months, NYPL Labs has embarked upon a series of investigations into how legacy classification systems at the library can be used to generate new data and power additional forms of discovery. What follows is some background on the project and some of the institutional context that has prompted these examinations. One of the tools we’re introducing here is “BILLI: Bibliographic Identifiers for Library Location Information;” read on for more background, and be sure to try the tool out for yourself.
Then there is a completely other type of distribution or hierarchy which must be called nomadic, a nomad nomos, without property, enclosure or measure. Here, there is no longer a division of that which is distributed but rather a division among those who distribute themselves in an open space — a space which is unlimited, or at least without precise limits… Even when it concerns the serious business of life, it is more like a space of play, or a rule of play… To fill a space, to be distributed within it, is very different from distributing the space. —Gilles Deleuze, Difference & Repetition
Classification, the basic process of categorization, is simple in theory but becomes complex in practice. Examples of classification can be seen all around us, from the practical use of organizing the food found in your local grocery store into aisles, to the very specialized taxonomy system that separates the hundreds of different species of the micro-animal Tardigrada. At their core these various systems of categorization are simply based on good faith judgments. Whoever organized your local grocery thought: “Cookies seem pretty similar to crackers, I will put them together in the same aisle.”
A similar, but more evidence based process developed the system that categorizes hundreds of thousands of biological species. Classification systems are usually logical but are inherently arbitrary. Uniform application of classification is what makes a system useful. Yet, uniformity is difficult to maintain over long periods of time. Institutional focus shifts, the meaning of words drift, and even our culture itself changes when measuring time in decades. Faced with these challenges, in the age of barcodes, databases, and networks, the role of traditional classification systems are not diminished but could benefit by thinking how they could practically leverage this new environment.
Problem Space
Libraries are founded on the principle of classification, the most common and well known form being the call number. This is the code that appears on the spine of a book keeping track of where it should be stored and usually the subject of its content. The most well known form of call number is, of course, the iconic Dewey Decimal System. But there are many other systems employed by libraries due to the nature of the resources being organized and the strengths and weaknesses of a specific classification system. Just as there is no single tool for every job there is no universal system for classification.
The New York Public Library is a good example of that realization as seen in the adoption of multiple call number systems over its 120-year history. The very first system used at the library was developed in 1899 by NYPL’s first president, John Shaw Billings. He wanted to develop a system that could efficiently organize the materials being stored in the library’s soon-to-open main branch, the Stephen A. Schwarzman building. In fact, Billings also contributed to how the new main building should be physically designed:
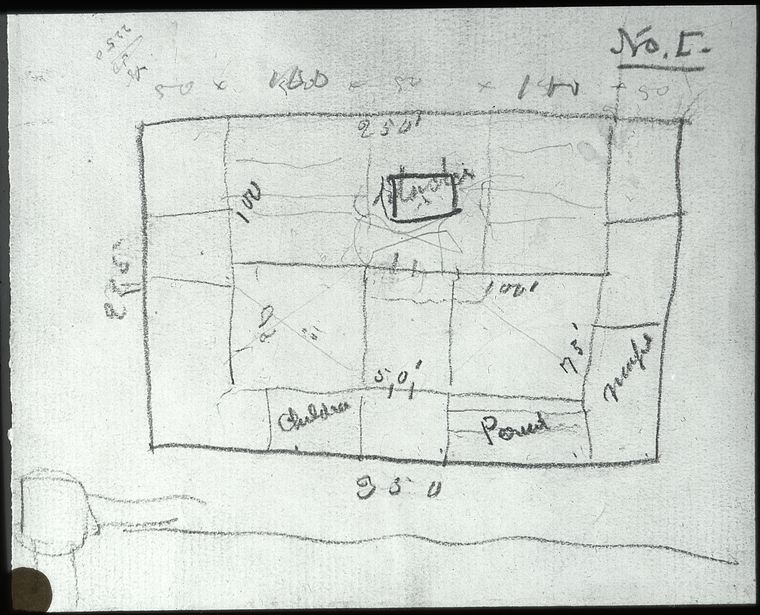
The classification scheme he came up with, known as the Billings system, could be thought of as a reflection the physical layout of the main branch circa 1911. Billings was very practical in the description of his creation, writing:
Upon this classification it may be remarked that it is not a copy of any classification used elsewhere; that it is not especially original; that is is not logical so far as the succession of different departments in relation to the operations of the human mind is concerned; that it is not recommended for any other library, and that no librarian of another library would approve of it.
The system groups materials together by assigning each area of research a letter, A-Z (minus the letter J, more on that later). This letter, the first part of the call number, is known as a classmark.
For example, books cataloged under this system that are Biographies would have the first letter of their classmark, “A”. History is “B”, Literature is “N”, and so on through “Z”, which is Religion. More letters can be added to denote more specific areas within that subject. For example, “ZH” is about Ritual and Liturgy and “ZHW” is more specifically about Ancient and Medieval Ritual and Liturgy.
While this system was used to classify the materials held in the main branch’s stacks, there were also materials held in the reading rooms or special collections around the building. To organize these materials, he reused the same system but added an asterisk in front of the letter to make what he called the star groups — i.e., a classmark starting with a “K” is about Geography, but “*K” is a resource kept in the Rare Books division though not necessarily about Geography. With these star groups, the Billings system became a conflation of a subject, location, and material-based systems. This overview document gives a good idea of the large range classification that the Billings system covered:

In the 1950s, the uptick in the acquisition of materials made the Billings system too inefficient to quickly catalog materials. While parts of the Billing system continued being used, even through to today, a general shift to a new fixed order system was made in 1956 and then refined in 1970.
The idea behind the fixed order systems is to group materials together by size to most efficiently store them. The library decided that discovery of materials could be achieved not by the classmark but by the resource’s subject headings. Subject headings are added to the record while it is being cataloged and provide a vector of discovery if the same subjects are uniformly applied.
In the United States the most common vocabulary of subject headings is the Library of Congress Subject Headings. Enabling resource discovery through subject headings obviates the need for call numbers to organize materials. The call number can just be an identifier to physically locate the resource. The first fixed order system grouped items only by size:

The call numbers would look something like “B-10 200”, meaning it was the 200th 17cm monograph cataloged. This system was refined in 1970 to included a bit more contextual information about what the materials were about:

Since the J letter was previously unused in the Billing system it was used here as a prefix to the size system to add more context to the fixed order classification. For example, a “JFB 00-200” means it is still a 17cm monograph but is generally about the Humanities & Social Sciences.
While this fixed order system is used for the majority of the monographs acquired by the library there are special collections in the research divisions that use their own call number systems. Resources like archival collections or prints and photographs have records in the catalog that help locate them in their own division. For example, archival collections often have a call number that starts with “MssCol” while rare books at the Schomburg Center start with “Sc Rare”. This final diverse category of classification at NYPL drives home the obvious problem: the sheer number of classification systems at work reduces the call number to an esoteric identifier—especially for obsolete and legacy systems—useful to only the most veteran staff member. These identifiers have great potential to develop new avenues of discovery if they can be leveraged.
A Linked Space
An ambitious 19th-century librarian faced with this problem might come up with a simple solution: Let’s invent a new classification system that incorporates all these various types of call numbers into one centralized system. With the emergence of linked data in library metadata practice, however, when relationships between resources are gaining increased importance, a 21st-century librarian has an even better idea: Let’s link everything together!
In most existing library metadata systems, the call number is a property of the record; it is a field in the metadata that helps to describe the resource. The linked data alternative is to make the classmark its own entity and give it an identifier (URI), which allows us to describe the classmark and start making statements about it. This is nothing new in the library linked data world; the Library of Congress for example, started doing this for some of their vocabularies (including some LCC classmarks) years ago. But to accomplish this task at NYPL it took a combination of technical work, institutional knowledge sleuthing, and a lot of data cleanup.
The first step is to simply get a handle on what classmarks are in use at the library. By aggregating over 24 million catalog records and identifying the unique classmarks, we are able to create a dataset that contains all possible classmarks at the library. This new bottom-up approach to our call number data enables the next step of organization and description.
Institutional knowledge is hard to retain over 120 years of history. It takes the form of old documents and outdated technical memos. The Billings classification was first documented in a schedule (a monograph book) that lists each classmark and its meaning. Some of these original bound resources are still around the library and have gone through their own data migration journey.

While the bound books are still in use today, most with copious marginalia, over the years this resource was converted to a typed document and then converted into the digital realm in the form of a MS Word document. This data was stewarded by our colleagues in BookOps who are the authority for cataloging at NYPL. We took this data and converted it into an RDF SKOS vocabulary and reconciled it with the raw classmark data aggregated from the catalog. This new dataset is comprehensive because it aligns what classmarks are supposed to be in use, from the documentation, with what is actually in use, from the data aggregation. Each classmark now has its own URI persistent identifier which we can begin making statements about:


All of these statements about our classmarks are hosted on a system we are calling BILLI: Bibliographic Identifiers for Library Location Information, an homage to NYPL’s mustachioed first president John Shaw Billings.
The BILLI system allows you to explore the classmarks in use at the library, traverse the hierarchies, and link out to resources in the catalog. But the real power of having our classmark information in this linked data form is the ability to start building relationships by creating new data statements.
A logged in staff member can add notes or change the description of a classmark but, more importantly, is able to start linking to other linked data resources. Right now, staff members are able to connect our classmarks to Wikidata and DBpedia, two linked data sources connected to Wikipedia:

The system auto-suggests some possible connections, here for the *H Library classmark, and the staff member can select or search for a more appropriate entity. Once connected, we pull in some basic information to enrich the classmark page:

As well as the the mapping relations:

Now that a link has been established we can use the metadata found in those two sources in our own discovery system and even apply some of it to the resources in our catalog that use this classmark. While the system is currently only able to build these connections with Wikidata/DBpedia, we can explore other resources that it would make sense to map to and expand the network to library and non-library based linked data sources.
While these classmark pages are here for us humans to interact with, computers can also “read” these pages automatically as they are machine readable through content negotiation. To a computer requesting *H data, the page would appear like this: http://billi.nypl.org/classmark/*H/nt
A Space of Play
If classification is arbitrary it is true there are a number of other systems that the library’s materials could be organized under. The only limitation is that it would be cost prohibitive to apply a new system to millions of resources. But in this virtual space, existing and even newly-invented systems can be easily overlaid and applied to our materials.
The first classmarks listed on BILLI are grouped under “LCC Range.” This classmark system is based on the existing Library of Congress Classification, a system which has historically not been used at NYPL. LCC is traditionally used at most research libraries, but because NYPL used the Billings and then Fixed Order systems it was never adopted here. Due to new linked data services, however, we were able to retroactively reclassify our entire catalog with LCC classmarks.
Using OCLC’s Classify—a service that returns aggregate data about a resource from all institutions in the OCLC consortium—we are able to find out a resource’s LCC classmark from other libraries that holds the same title. While we were not able to match 100% of our resources to a Classify result we were able to apply a significant number of LCC classmarks to our materials.
Of the materials for which we were unable to obtain a LCC, we can use some simple statistics to draw concordances between Billings and LCC. For example, if we have enough resources that have the same LCC and Billings classmark we can assume that the two are equivalent and apply that LCC to all the materials with that Billings classmark. One caveat is that LCC numbers can be very specific in their classification, much more so than Billings. What we need to do in order to map Billings to LCC is create more generalized, or coarser, LCC classmarks.
To accomplish this we parsed the freely available PDF LCC outlines found online into a new dataset with each classmark representing a large range of LCC numbers. Using this invented, yet still related, LCC range classmark we can map our Billings classmarks to their coarse LCC equivalents. Now, a researcher who is perhaps more familiar with LCC can easily navigate to corresponding Billings resources.
The LCC range classmark example represents an exciting opportunity to organize our materials in new ways within a virtual space. In this networked environment classification shifts from rigid hierarchy to a fluid interconnected mappings—the difference between dividing space and filling it.
Read E-Books with SimplyE
 With your library card, it's easier than ever to choose from more than 300,000 e-books on SimplyE, The New York Public Library's free e-reader app. Gain access to digital resources for all ages, including e-books, audiobooks, databases, and more.
With your library card, it's easier than ever to choose from more than 300,000 e-books on SimplyE, The New York Public Library's free e-reader app. Gain access to digital resources for all ages, including e-books, audiobooks, databases, and more.
If you don’t have an NYPL library card, New York State residents can apply for a digital card online or through SimplyE (available on the App Store or Google Play).
Need more help? Read our guide to using SimplyE.
Comments
Thanks for the description.
Submitted by Jakob Voß (not verified) on January 28, 2016 - 5:23am
Hi, thanks for reading!
Submitted by Matt Miller on January 28, 2016 - 12:48pm